When designing a feature store, the end goal is to generate denormalized tables for consumption. As a design principle, we need to be able to slice data at any “point-in-time” for the purposes for scoring and simulating production. It’s important to consider the nuances in designing a feature store, particularly when differentiating between how practitioneers may build modelling datasets and how modelling datasets may be deployed.
For example, if the deployment pattern is to be run on a weekly basis, then the labels generated in time should reflect the deployment pattern. As a simple example, if are predicting the customer behaviour tomorrow, and scoring happens on a weekly basis, we can only guarentee that our predictions are suitable at the point of scoring. On the other-hand, if we are predicting customer behaviour within the next 28 days, and scoring is done weekly, then we are functionally predicting a customer’s behaviour between 21-28 days (depending on the date of trigger or how the features are generated).
This distinction is important when considering how denormalized tables are built and how scoring mechanism is considers.
Here is a simple example which demonstrates this.
# %matplotlib inline
import pandas as pd
import numpy as np
from plotnine import *
time_daily = pd.date_range('2018-01-01', periods=90, freq='D')
time_weekly = pd.date_range('2018-01-01', periods=90//7, freq='W')
offset = pd.to_numeric(time_daily)[0]
offset2 = (pd.to_numeric(time_daily) - offset)[1]*35
behaviour_daily = np.sin(pd.to_numeric(time_daily)/3000) + (pd.to_numeric(time_daily) - offset)/offset2
behaviour_weekly = np.sin(pd.to_numeric(time_weekly)/3000) + (pd.to_numeric(time_weekly) - offset)/offset2
daily_data = pd.DataFrame({
'Event': time_daily,
'Behaviour': behaviour_daily,
'Granularity': 'daily'
})
weekly_data = pd.DataFrame({
'Event': time_weekly,
'Behaviour': behaviour_weekly,
'Granularity': 'weekly'
})
weekly_data = pd.merge(daily_data[['Event']], weekly_data, how='left').ffill()
(ggplot(pd.concat([daily_data, weekly_data]), aes('Event', 'Behaviour', color='Granularity')) + geom_line(size=1) + theme_bw())
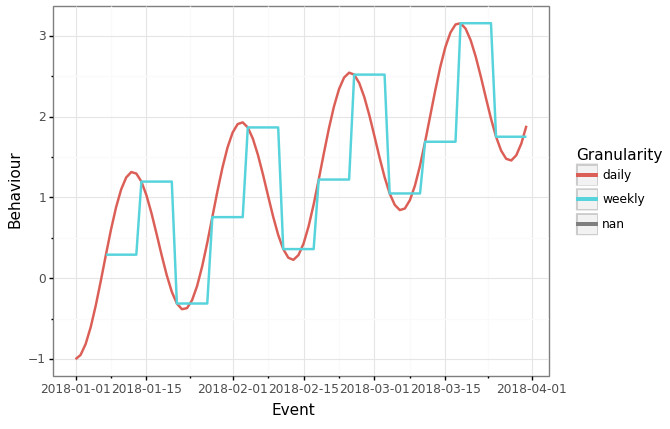
What this means is that the design of the feature store must also take into consideration how users will build and deploy models as well! Through modelling this appropriately, one can set appropriate expectations and have more reliant metrics before moving ot production.
Some of the drawbacks of this approach is that the features which are served ought to be thought of as “best efforts” rather than the definitive truth. This has nice-ties when we think about loose coupling among different components, however we need to set up expectations for the actual serving of features and the downstream impact that might have on production-grade AI.